Dịch vụ gắn nhãn dữ liệu
Viện Nghiên cứu Tổ chức và Kinh tế số (RIDE) là đơn vị nghiên cứu và triển khai các giải pháp về kinh tế số, trí tuệ nhân tạo (AI) và quản trị dữ liệu. Với sứ mệnh thúc đẩy ứng dụng AI tại Việt Nam, RIDE cung cấp dịch vụ gắn nhãn dữ liệu chuyên nghiệp cho các tổ chức, doanh nghiệp và dự án phát triển mô hình học máy, giúp biến dữ liệu thô thành dữ liệu có cấu trúc, sạch, và sẵn sàng cho huấn luyện AI.
Các đặc điểm của dịch vụ gắn nhãn RIDE
Độ chính xác và tính nhất quán cao:
Quy trình gắn nhãn được thiết kế nhiều tầng kiểm định (multi-level validation), bao gồm kiểm tra chéo, đánh giá ngẫu nhiên và phản hồi vòng lặp, đảm bảo dữ liệu đầu ra đạt chuẩn chất lượng huấn luyện mô hình AI.
Tích hợp công cụ thông minh:
RIDE phát triển và vận hành nền tảng quản lý gắn nhãn dữ liệu DLMS hỗ trợ quy trình tự động, thống kê hiệu suất và cảnh báo sai lệch. Hệ thống tích hợp AI hỗ trợ gợi ý nhãn giúp tối ưu chi phí và thời gian.
Quản trị chất lượng theo thời gian thực:
Mọi thao tác gắn nhãn được ghi nhận, theo dõi và thống kê theo người dùng, giúp đội ngũ kiểm định đánh giá chính xác năng suất và độ tin cậy của từng cộng tác viên.
Đội ngũ chuyên môn đa lĩnh vực:
RIDE hợp tác chặt chẽ với các trường đại học để huy động sinh viên và giảng viên theo đúng chuyên ngành dữ liệu (ngôn ngữ, kỹ thuật, y học, nông nghiệp, sản xuất...). Điều này giúp dữ liệu được gắn nhãn chính xác về mặt nội dung, ngữ cảnh và thuật ngữ chuyên ngành.
Tuân thủ nghiêm ngặt các tiêu chuẩn bảo mật dữ liệu quốc tế:
Mọi dự án đều được triển khai trong khuôn khổ tuân thủ các quy định bảo vệ dữ liệu và quyền riêng tư của từng khu vực:
- Việt Nam: Nghị định 13/2023/NĐ-CP về bảo vệ dữ liệu cá nhân, Luật An ninh mạng 2018.
- Liên minh Châu Âu (EU): Quy định Bảo vệ Dữ liệu Chung (GDPR).
- Hoa Kỳ: Tuân thủ CCPA (California Consumer Privacy Act) và các nguyên tắc của NIST về quản lý dữ liệu.
- Hàn Quốc: Đáp ứng tiêu chuẩn PIPA (Personal Information Protection Act).
- Nhật Bản: Tuân thủ APPI (Act on the Protection of Personal Information).
- Toàn bộ nhân sự tham gia dự án đều ký thỏa thuận bảo mật (NDA) và làm việc trên hệ thống kiểm soát truy cập phân tầng (role-based access control).


Các loại dữ liệu RIDE xử lý
- Dữ liệu hình ảnh và video: Nhận diện vật thể, phân vùng (segmentation), gắn nhãn hành động, kiểm định chất lượng sản phẩm.
- Dữ liệu văn bản: Phân loại chủ đề, trích xuất thực thể (NER), phân tích cảm xúc, gắn nhãn ngữ nghĩa và hội thoại.
- Dữ liệu âm thanh: Nhận dạng tiếng nói (ASR), gắn nhãn cảm xúc, hội thoại và ngữ cảnh tiếng Việt đa vùng miền.
- Dữ liệu chuyên ngành: Gắn nhãn kỹ thuật trong các lĩnh vực nông nghiệp, y tế, giáo dục, công nghiệp sản xuất, hành chính công
Quy trình gắn nhãn dữ liệu tại RIDE
1
Khảo sát và phân tích dữ liệu đầu vào
Đánh giá chất lượng dữ liệu, xác định mục tiêu huấn luyện mô hình. Thống nhất phạm vi và chi phí.
2
Thiết kế quy trình gắn nhãn và khung dữ liệu mẫu
Thiết lập hướng dẫn chi tiết cho từng loại dữ liệu, đảm bảo quá trình gắn nhãn thống nhất
3
Gắn nhãn dữ liệu theo quy trình chuẩn
Thực hiện bởi đội ngũ nhân viên và cộng tác viên được đào tạo theo chuyên đề
4
Kiểm định chất lượng và xử lý phản hồi
Thực hiện các bước kiểm tra xác suất, kiểm tra chéo, xử lý phải hồi của khách hàng
5
Bàn giao dữ liệu chuẩn hóa
Dữ liệu đầu ra được cung cấp theo định dạng yêu cầu (JSON, CSV, XML, v.v.) kèm báo cáo chất lượng
Hệ thống và công cụ hỗ trợ
-
Nền tảng RIDE Data Labeling Management System (DLMS):
- Quản lý phân quyền, giám sát tiến độ, thống kê hiệu suất.
- Hỗ trợ đa dạng kiểu gắn nhãn: bounding box, polygon, keypoint, entity extraction, text classification.
- Tích hợp công cụ AI hỗ trợ gợi ý nhãn (AI-assisted labeling) giúp tăng tốc quy trình.
- Môi trường làm việc bảo mật và mở rộng linh hoạt, có thể triển khai theo mô hình on-premise hoặc cloud tùy nhu cầu khách hàng.
- API kết nối mở giúp tích hợp dễ dàng với hệ thống huấn luyện AI của đối tác.


Điểm khác biệt về chất lượng gắn nhãn của RIDE
RIDE hợp tác với nhiều trường đại học trong nước để đào tạo và huy động đội ngũ sinh viên gắn nhãn chuyên môn hóa theo lĩnh vực, bảo đảm mỗi dự án đều có nhân sự am hiểu nội dung dữ liệu (ví dụ: sinh viên nông nghiệp gắn nhãn dữ liệu cây trồng, sinh viên y học gắn nhãn hình ảnh X-quang…).
Các cộng tác viên được đào tạo chuẩn hóa theo khung kỹ năng gắn nhãn dữ liệu của RIDE, bao gồm kỹ năng kỹ thuật, kiểm tra chéo, và bảo mật thông tin.
Một số dự án tiêu biểu

Nhận diện hành vi trong khu vực công cộng
Gắn nhãn video từ hệ thống camera giám sát để huấn luyện mô hình phát hiện hành vi bất thường, tụ tập đông người, hoặc bạo lực.

Nhận diện phương tiện giao thông vi phạm luật
Gắn nhãn ảnh và video để huấn luyện hệ thống nhận diện biển số xe và phát hiện vi phạm giao thông tự động.

Ứng dụng AI trong kiểm soát ra vào cửa khẩu
Dữ liệu huấn luyện cho hệ thống nhận diện khuôn mặt, biển số xe một số nước Châu Á, xác thực danh tính đa yếu tố.
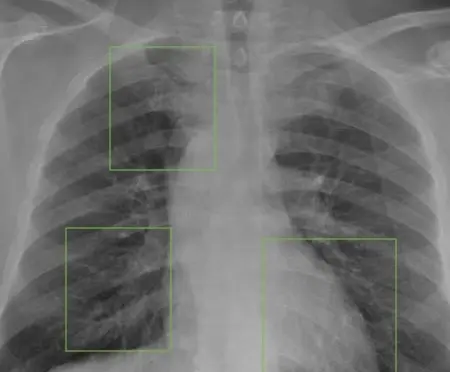
Gắn nhãn ảnh chẩn đoán X-quang
Cộng tác với giảng viên, sinh viên y khoa và bác sĩ chuyên ngành chẩn đoán hình ảnh để gắn nhãn vùng tổn thương, khối u, hoặc dấu hiệu viêm.
Phân loại hồ sơ bệnh án điện tử
Làm sạch và gắn nhãn văn bản y khoa nhằm huấn luyện mô hình trích xuất thực thể y tế (thuốc, bệnh, chỉ số lâm sàng).

Trợ lý y tế ảo
Gắn nhãn dữ liệu hội thoại giữa bệnh nhân và bác sĩ để huấn luyện mô hình AI giao tiếp y tế an toàn và chính xác.

Nhận diện lỗi bề mặt sản phẩm cơ khí
Gắn nhãn hình ảnh từ dây chuyền kiểm tra camera công nghiệp để phát hiện vết nứt, sai lệch, trầy xước trên sản phẩm.
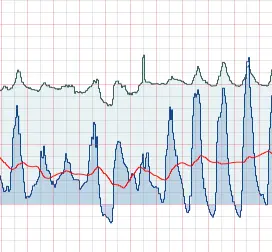
Bảo trì dự đoán
Gắn nhãn tín hiệu âm thanh, rung động từ máy móc, và các tham số từ thiết bị IOT để huấn luyện mô hình dự báo sự cố sớm.

Phân tích văn bản và tài liệu học tập
Gắn nhãn nội dung giáo trình, bài giảng, câu hỏi để xây dựng mô hình gợi ý xây dựng infographic cho học liệu số

Hỗ trợ chấm điểm tự động
Làm sạch và gắn nhãn tập dữ liệu bài thi tự luận, hỗ trợ huấn luyện mô hình chấm điểm tự động và đánh giá năng lực môn ngữ văn